ye lol
edits:
had a package come empty whole thing exploded out of the envelope lol so now i get to be amazon karen like @TheDiddilyHorror
made a quick video for youtubes lol
forgot to add the singing

ye lol
edits:
had a package come empty whole thing exploded out of the envelope lol so now i get to be amazon karen like @TheDiddilyHorror
made a quick video for youtubes lol
forgot to add the singing
Gunna make a meme video soon that’s Carmen Sandie go SMV {Seinfeld music video}
like the bass theme?
edits:
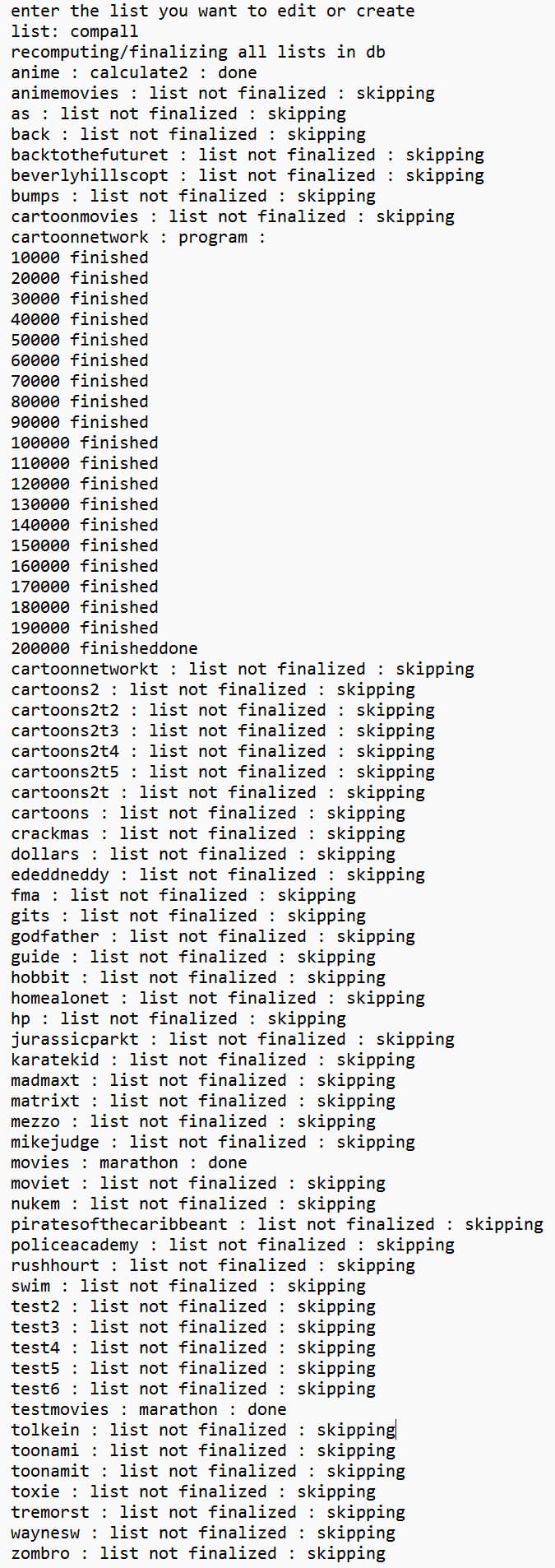
after thinkin about the thingie some more. think decided on instead of having it auto update/re-finalize lists when you edit one that would effect other lists. think simpler and less compromising the goals on keeping it more simple format and stuff
to just make a command that updates every list, the other than the new code to do that, only change would be edit the index file to contain a number to denote the type of finalizing you did on that list, if you had, if you had modified it but not finalized it yet, have it display that info at the bottom of the table that shows the list contents when you are in the program, so you know which one you did last time etc
which is fairly minor format change, and to the index file which isnt the one i cared about really, was more the actual list format itself, the index is just so the program knows how to create the list, which lists if its multiplied/how many times etc. and this will be simple too just a number and a symbol maybe to detect if its there more reliably, and update the file if there isnt one(wont be necessary anyways since no one would be using it with lists that dont follow that format but, catch error and repair it in one shot)
op edit:
will take longer than only updating the lists that were affected, but that is the laziest way to do it if you are gonna be lazy and let it do it for you anyways, dont take long anyways so no big deal time wise unless you had many super long lists(bein on my athlon 200ge 3.2ghz zen 1, does over 10k placements per second in the slower calculate modes) so normal list of movies by category or whatever type of things will be done in normal calculator ‘instant’ on basically any modern computer
Yeah that rockapella did
coo lol
edits:
gonna take some notes/think a bit though if gonna mess with the format for the index anyways might double check some stuff, primarily how it does the multiplier detection and how many entries per list/index
maybe put in a number to say how many there is, maybe a symbol like * or something to denote a multiplier entry will follow, as well as the finalization/export type, if have to manually fix all my indexes anyways probably might as well do upgrades if i can at same time
edit2:
hadnt looked at it in forever but it does reference the location so unless they gave a full path its db\listname for the entries so theres no conflict with the raw numbers(wasnt sure if had made sure that wouldnt be an issue, incase someone made a list with only numbers like 007 or something)
so might just leave that alone, does have a * for the duplication list option(s) forgot XD. but end of the file would work or just a different character maybe = would make sense in a way, some something like if detect end of file the type is 0, or if it reads = the next entry is the type, probably at the end of the file anyways
ye ended up bein = lol but got it that part in somewhat still doin busy work for it mostly now, got it in for the rand function(as test), then the end part of the main loopy bit there, where it does add/remove by name the list you entered, or move/duplicate multiply etc.
might be another one or 2 gotta do special thing for but all the main finalizing/exporting was the same bits of code for removes the multiplier from the index to get a nice list, then add it back when done, so already got that good from rand, to just treat that as a multiply number and remove from the working list, then write back updated number when done
edits:
doin full scale testing now messin with puttin in a timer/formatting and stuff
the not finalized is just for ones you never exported(or didnt have the = and number format for that) in which case it doesnt know what type to do, so they gotta finish editing and export that list then next time it will do it how they did it the last time
was doin it on the new laptop just for funzies so tiny resolution so had it print the output to a text file so no proper screenshot yet
got the done format thing fixed, but takin a stop and think for awhile on it, decide if do a simple, add another command like instead of compall have compallx and then it asks for a number then it goes that many times, vs trying to simplify indexing to be able to recursively search/list the, lists which reference other lists, what order they are in which is the lowest to highest, prevent issues if a user were to make a list that references a second list which references the first list creating some kinda infinite loop index
thinkin compallx but maybe somethin else will come to me, already ruled out doin some other sort method like by size(since movie lists would be more likely to contain many other lists), maybe could do by the actual data for how many segments/files would be in it not the number of entries/lists would probably be more reliable but not 100%.
the compallx option would just be you figure out or just remember, what is the maximum nested list you have and run that many times, say you had toy story in cartoon movies in cartoons in cartoon network, if you entered do it 4 times, regardless of any sort it would do it 100% of the time. is wasteful cpu wise, but other than that one list thats 200k there it would only be like 2 seconds to do all the other lists combined, and like 20max for that long one(like 40 on laptop set to 6w lol), so if they just said like 10x would only be couple min unless they had really long, or many really long lists, which you would only do when you did many changes that you are too lazy to track yourself
ended up adding one more number after the one sets the mode, to describe a depth level, which is just 1 higher than the highest in that list. so detection for looping/chaining loop etc lists, is just if a gap appears between 1 and whatever the highest number is then theres somethin not right. else you just redo running thru them all equal to the highest depth.
probably gonna add a -f to force it to do it now, since had the -a(after) option forever, but with the newer scheduled mode, in case they have a media player choice that doesnt have a press q to quit instantly like mpv
edits: stopped bein lazy and figured out the timer stuff so now it says per list if you run one, or the comp all per list, and a total time, in seconds.ms, minutes.seconds.ms if its over a 59 seconds
edits:
isnt accurate if the total time is below like .1 second elapsed, but its mainly for the total elapsed time so dunno if i care about that one XD
havent looked to see whats in my kernel on arch to see what timers are available/what speeds but looks like still normally only like .001 is the faster(ist maybe) option, but at a speed of ~10000 a second even for longer lists where there is order of magnitude more data to scan past to get to the correct entries, not sure how i would measure the speed to tell, but shorter ones below 10 obviously would be shorter than .001 s, bein its like .0001 to place even for really long lists, possibly even faster depending on list, maybe like 50-250 or something could be within that first ms even on my slow laptop
mostly just for fun/if you have very large data sets/lists maybe be useful in a verbose output, if one used to take longer but now its really short maybe it got edited incorrectly or something to make it smaller idk
Due to unforseen circumstances we experienced data corruption from the main storage drive for the forum and despite my best efforts I was unable to recover any data from the drive, this unfortunately means we’ve lost about 5 months worth of data for the forum. I am currently putting in measures to mitigrate this including a more robust backup system to hopefully prevent this happening in the future.
I am sorry for any inconvenience casued and if you want to repost anything that was lost in the meantime please feel free todo so.
should be fine just bunch stuff from me and the diddleman
What’s happenin’, everyone?
Been kinda busy with work myself.
Had my employee dialogue this week.
The good news is that my fixed-term contract will be changed to a permanent one at the end of the year because both my section chiefs are overall very happy with my work performance.
The bad new is I have to socialize more at work with other secretaries…
Other than work and playing Diablo 4 there’s not much happening in my life.
I got clear aligners about a month ago and now I sound like I have a lisp when I talk.
the sarsaparilla flows salaciously on saturdays
just work had a almost get super pissed event with the drawring tablet lol, had some piece of no idea little very very thing black bit between the layers of screen fell between the front glass and the lcd(has a extra thick glass piece added to the front they glue on putting the screen in i think, it doesnt unscrew from back/isnt removable from the back the pane holds it in the frame just the pcb and wire connections are in the back bit you can open)
fell in front of the usable area like a whole line of ded pixels or somethin but i bumped it(sometimes if you slightly bump stuck whatev pixels can do stuff) and it moved, and if hold at far angle could see underneath it like light behind the black piece that clearly its infront of the lcd, but no way to remove the glass without solvents or somethin prolly, other than risking it breaking and then possibly damage lcd etc, but i got it back out of view for now atleast
edits: is past that point of like first 30days or whatever where you could just instantly get a new one claiming a defect or whatever, would have to actually send away for warranty service to china for them to try and diagnose/fix
second edits:
tried on it after waiting awhile(Was planning on it) got it back in the bezel area and hasnt fallen down in couple days but no idea how it fell down in first place so will see i guess, but so far so good ![]()
so far after i bumped the thing out of sight for the drawing tablet, nothing came back yet so dunno lol back to pretty happy with it just bizarre happend it first place
finally took some time after busy as week, did little bit of it during the week but mostly yesterday and this morning workin on the perfect loop thing for the program mode, since bunch of that work can be reused for the divide functions did that one first
some more testing and gotta comment out the debugging output stuff should be fast enough for that part doesnt warrant having any output before total segments(if isnt already before it does the final placement stuff move it up)
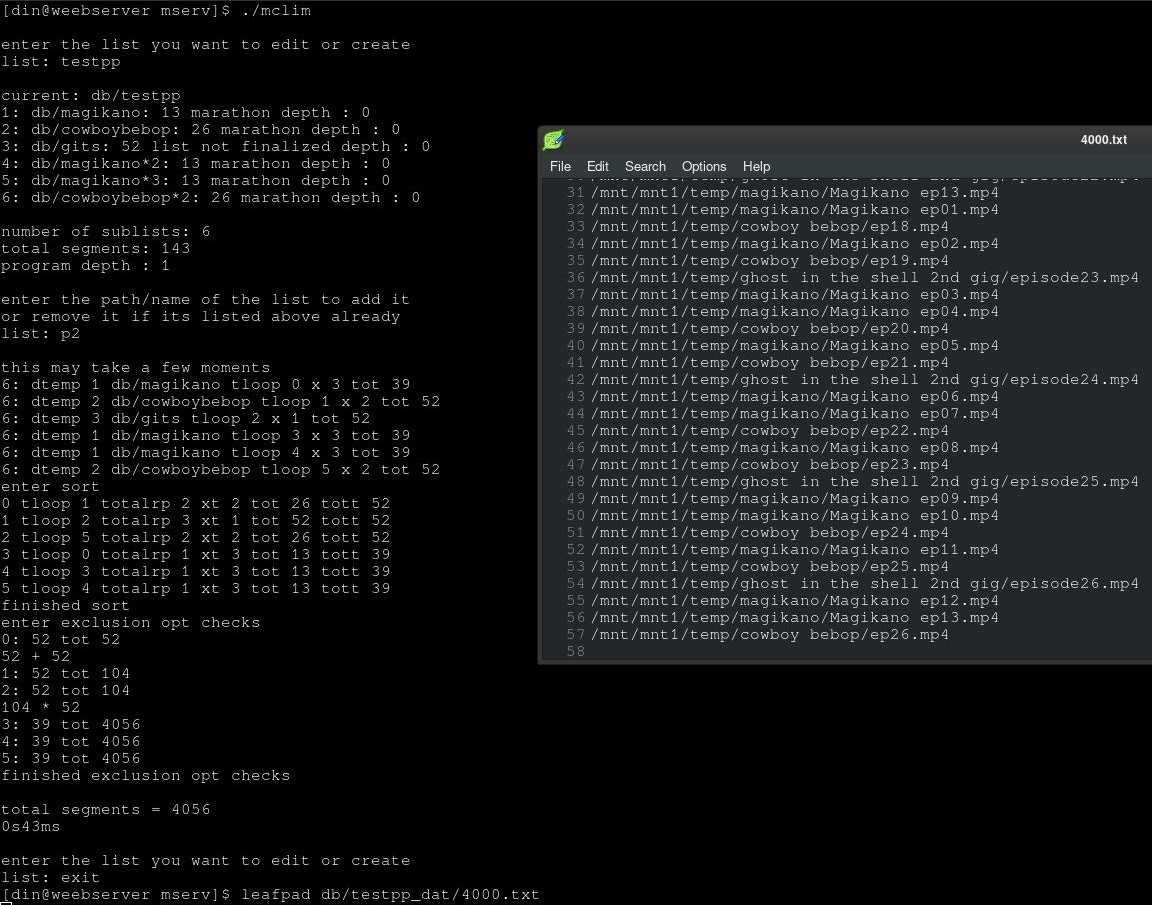
edit:
lel some the debugging output was printing the first number instead of the second one(has 2 running numbers at a time for checking if its equal to or the second divides with no remainder) but the numbers was right/half of it was showing the right so knew what it was doin
gotta do more testing in random numbers and stuff, double check the overflow protection and stuff(since it can make super massive numbers very fast like 6 7 8 9 10 11 13 17 is like 6,125,000, i mean upper limits of long long is pretty good like 18 whole digits and a partial 19th, but might put in a opt out warning or something if its big like over a mil or somethin idk have to think about it i guess
edit2: had a lel moment actually worked first hit on this last situation to account for when i went back to it after eatin
was workin on multi list entries of same length exclusion stuff, if you have multiple entries of the same length that are different lists, that also have multiple entries of the same list, to exclude the other ones its not even checking yet/then skip checking them later. and double checking/fixing conditions for multiple lists of same length for the math by moving it out of the inner exclusion checking loop to the one right past it(it reads in one entry from list then compares to all other entries beneath it that arent excluded already) and then enters the inner multi check/condition loop parsing all the rest of the numbers
so now it does all strictly divisible numbers corrently in one pass, as bascically every divisible number is increase the length by the longest number that divides into, say 52 if you had a 26 or a 13 you have to increase by 52 every time, as this is the number of episodes that play not the number of loops, if you add 26 episodes to that 52, you have to play the 26 twice to have the 52 end at the end at same time as the 26, the 13 would just play 4 times to make up the difference but then all end at the same time again
gotta check for multiple occurrences of same length in divisible ones tho but should be mostly same deal
multiedits later:
messed with it in theory was workin but not in results, although that earlier one worked put a more complicated list to have every scenario at once bascially, divisible, multi divisble, multi divisible with multi entry, single entry with no divisible with anything, multi entry not divisible with anything, was getting a number did perfectly divide all of them but they werent ending at the same, tryin a that number x the number of entries seems to work so far but idfk semi advanced maths or something
bunch later edit:
looks like still workin but tryin some testing looks like should be fine to refactor the code to just not bother with the duplicate ones and just treat them as the same(basically was doin the same math anyways in the end) just for readability in the future having less possible conditions to check for, also some specific scenario can make the thing shorter by not treating them as the longer length, like if it was for a 13 but longest list is 24, having a 13x3 would be 39 would end up like 39 * number of divisible lists so 13 or whatever also increases by 39 every time before it would then multiply that total by 24
so sometimes shorter, but mostly easier to read, and will be more similar to the other part for the divide stuff when start working on that, since that would never have the duplicate stuff either
bedit2: was messin with refactoring and doin some testing while gettin it goin noticed it seemed to work even when it was way simpler/part wasnt working
seems like might work if just do each highest [unique non divisible into another number](e.g. if had 52 26 and 13 ignore the lower divisible numbers and just count 52) times every other [highest unique number], then at the end times the [total the number of entries] in total(including all the excluded ones)
so far seemin to work but gotta do testin before finalize obviously, makes sense mostly, in that its a number is divisible by every entry, and that final times all entries, is how many entries is 1 loop, and trying to get it to have them all end within 1 loop got the other way workin same as before can just change comment out to try different ones to compare currently, just tryin to get it to the lowest number that works reliably, if just multiply all of them will work every time is just exponentially larger
My horror movie collection has grown quite a lot in the last few months.

Top, middle and the left side of the bottom shelf are all horror movies.
Top is movies with multiple parts.
Middle and bottom left has single movies.
I translated the German titles but didn’t bother to put them in alphabetic order.
30 Days of Night
What we do in the Shadows
A Nightmare on Elm Street
A Serbian Film
A Silent Place Part I
A Silent Place Part II
American Psycho
Annabelle 1
Annabelle 2 - Creation
Annabelle 3 - Coming Home
Baba Yaga
Behind You
Black Christmas (Jessy - Die Treppe in den Tod) (3 Schnittfassungen)
Bram Stoker’s Dracula
Child’s Play
Child’s Play 2
Child’s Play 3
Child’s Play 4
Child’s Play 5 - Chuckys Baby
Child’s Play 6 - Curse of Chucky
Child’s Play 7 - Cult of Chucky
Close Calls
Coraline
Crimson Peak
The Blob
The Thing
The Relic
The Exorcism of Emily Rose
The Exorcist
The Grudge 1
The Haunting
Jaws
Color out of Space
In the Mouth of Madness
The Ninth Gate
The Devil’s Blackcoat
Drag Me To Hell
Evil Dead - Army of Darkness
Evil Dead 1
Evil Dead 2
Evil Dead Rise
Final Desitnation 1
Final Desitnation 3
Final Desitnation 5
Final Destination 2
Final Destination 4
Freddy Vs. Jason
Friday the 13th - Jason Goes To Hell
Friday the 13th - Jason X
Friday the 13th, Part I
Friday the 13th, Part II
Friday the 13th, Part III
Friday the 13th, Part IV
Friday the 13th, Part V
Friday the 13th, Part VI
Friday the 13th, Part VII
Friday the 13th, Part VIII
Fright Night 1
Fright Night 2
Ghostland
Grave Encounters
Gremlins 1
Gremlins 2
Gretel & Hänsel
Hagazussa
Halloween
Halloween Kills
Halloween Ends
Hannibal Lecter - Silence of the Lambs
Hannibal Lecter - Hannibal
Hannibal Lecter - Red Dragon
Happy Death Day
Happy Death Day 2U
Hereditary - Das Vermächtnis
Hostel Part I
Hostel Part II
Hostel Part III
House on Haunted Hill
Inside
Insidious: Chapter 2
Insidious: Chapter 3
Insidious - The Last Key
It Follows
Jeepers Creepers 1
Jeepers Creepers 2
Jeepers Creepers 3
Jeepers Creepers - Reborn
As Above, So Below
Krampus
Lake Bodom
Leatherface
Lights Out
The Curse of La Llorona
Look Away
M3GAN
Martyrs (Original)
Midsommar (Director’s Cut)
Mutant Chronicles
Nightmare On Elm Street 1
Nightmare On Elm Street 2
Nightmare On Elm Street 3
Nightmare On Elm Street 4
Nightmare On Elm Street 5
Nightmare On Elm Street 6
Nightmare On Elm Street 7
Open 24 Hours
Ouija 1
Ouija 2 - Origin of Evil
Pandorum
Paranormal Activity 1
Paranormal Activity 2
Paranormal Activity 3
Paranormal Activity 4
Polaroid
Poltergeist
Possession - Das Dunkle in dir
Psycho
Raw
REC
Repo! - The Genetic Opera
Resident Evil - Welcome to Raccoon City
Resident Evil 1
Resident Evil 2 - Apocalypse
Resident Evil 3 - Extinction
Resident Evil 4 - Afterlife
Resident Evil 5 - Retribution
Resident Evil 6 - The Final Chapter
Ring 1
Ring 2
Rings
Rosemary’s Baby
Scream
Scream 2
Scream 3
Scream 4
Scream 5
Scream 6
Seance
Shallow Ground
Silent Hill
Silent Hill - Revelation
Sinister
Sinister 2
Sissy
Slaxx
Sleepy Hollow
Smile
Stephen King’s The Fog
Stephen King’s IT
Suspiria
Terrifier
Terrifier 2
Texas Chainsaw - Unrated Version
Texas Chainsaw Massacre
Texas Chainsaw Massacre 2
1BR
The Autopsy of Jane Doe
The Black Phone
The Cabin in the Woods
The Conjuring 1
The Conjuring 2
The Conjuring 3
The Devil Inside
The Entity
The Fog - Nebel des Grauens
The Frighteners (Kinofassung + Director’s Cut)
The Hole in the Ground
The Lodge
The Nun
The Pope’s Exorcist
The Possession of Hannah Grace
The Reckoning
The Song of Solomon
The Unborn
The Unholy
The VVitch
The Wailing - Die Besessenen
The Witch Next Door
Truth or Dare ?
We are the Night
Wrong Turn 1
Wrong Turn 2 - Dead End
Wrong Turn 3 - Left for Dead
Wrong Turn 4 - Bloody Beginnings
Wrong Turn 5 - Bloodlines
Wrong Turn 6 - Last Resort
Wrong Turn - The Foundation (Reboot)
X
Room 1408
isnt that the one on youtube people are like is super lewd but its not that bad actually?
think ju-on(the actual jap cable company original version of grudge) actually decent, is more complicated like multi part thing, then just a kid thats blue in one house or whatever
Dunno. Only read that it’s supposed to be like Hostel and some people on Reddit think it’s worse (more gore, more violence, etc).
ju-on stuff
not really gore/the actual deaths that much, but to spoiler is basically its more about the supernatural whatever ‘creature’ part of the thing then its that one house is bad juju, like some lady visiting there to check on the old lady living there/missin kid or somethin(forget) ends up getting got, then later at her apartment building theres now blu lady, somethin like if they see/get attacked by them but escape they can show up later where they are then and if they die there then can attack people near there. like different rules then i remember the american remake one being
guessin you were actually replying to serbian film bit? ye sounds like that forget what the thing was, like incest rape or somethin was like a one ‘extra bad’ thing i thought
but if i resort and have a new total tally, i can just not have to skip them at all by only having a list of the ones we need to check, but is fast as hell either way since its c and its doing a pretty small loop, should be able to do in the hundreds of thousands maybe million of checks per second on this athlon 200ge system
thats much faster than if you get the number way off and its like 1000x longer than it needed to be at that like 5000~10000 places per second actually fully computing/compiling the list
edits:
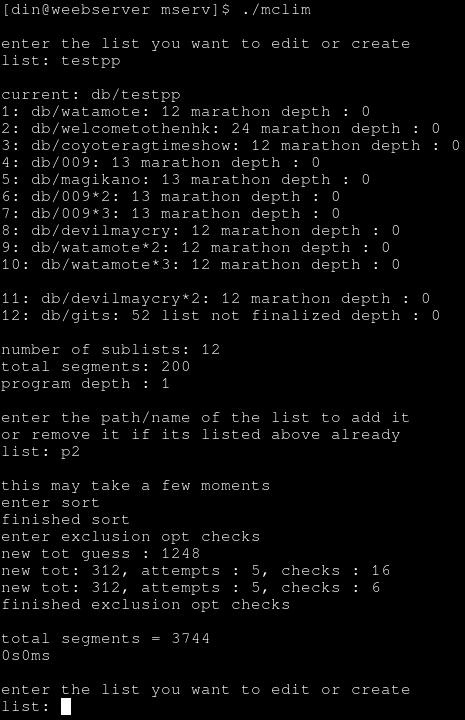
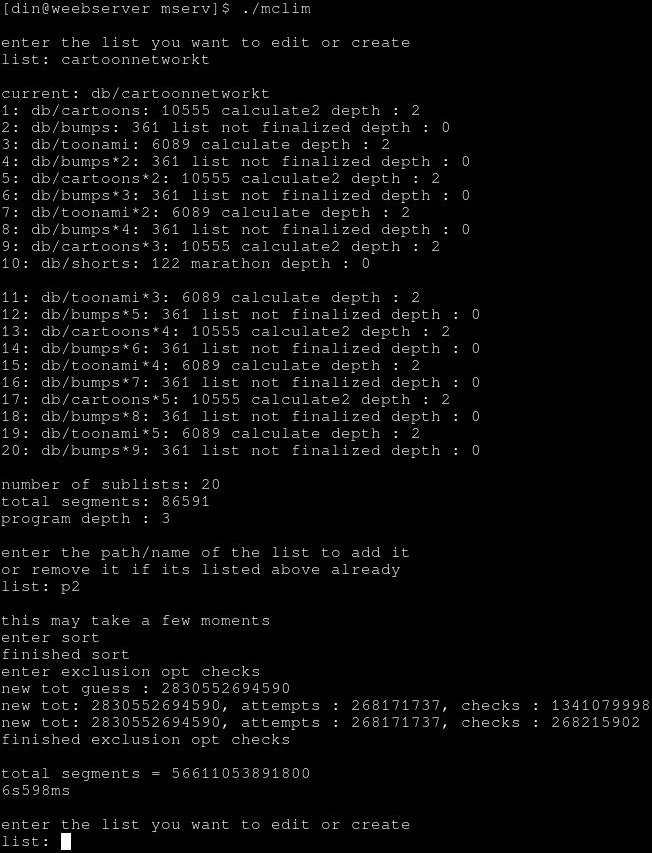
did a test build with optimized and unoptimized so i could compare couple scenarios for fun, was fair amount of reduction still in some instances, even though the sorting it first did most of the optimization, would be the checks number to be looking at, the attempts is the number of times it incremented the number that it then checked with the division/modulus thing to see if the numbers were divisible in the long one was like 1~1.5seconds or something and the rest of the time was the other one lol
gotta decide what wanna do for a prompt, but to for sure have something to pop up sayin that number is crazy high are you sure/option to put in a different number or something
for example, in the long one just the data files for this list would be like 1~5PB probably lol, bein its like 56 trillion entries, and 1 byte per character if you said average full path/file name was 30 characters per line thats 30*56(TB)=1680TB and a play time for it to loop one time like 2.6 some billion years at 25min average per entry
feel like once it goes past like ~250k entries where you talkin in the realm of probably 2~5years if its around normal television segment length average, that probably as big as it needs to be, as the user would add/change stuff well within that time probably
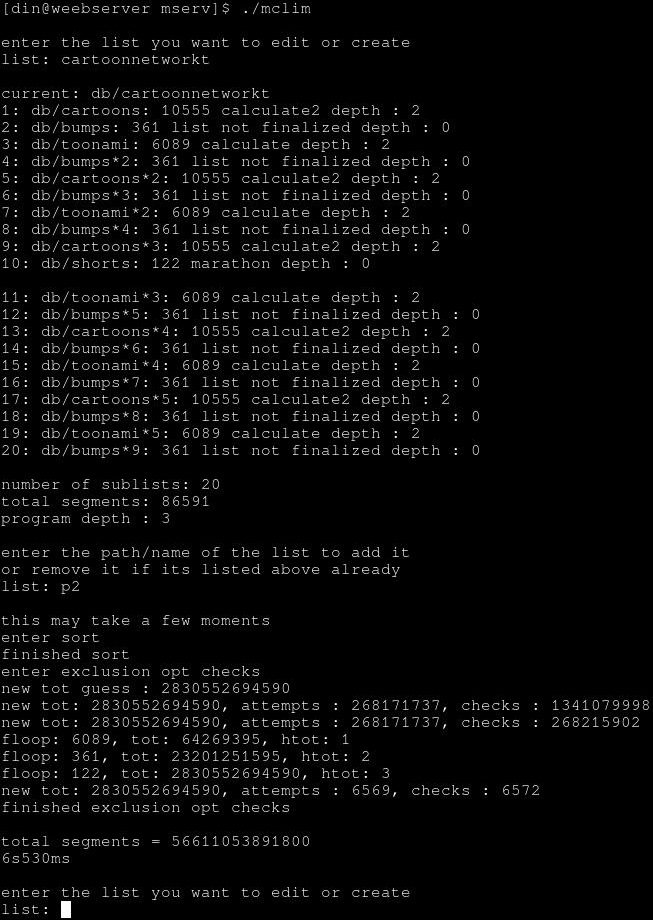
had another idea for optimizing the actual loop itself after removing duplicates and stuff could easily remove in the earlier pass, to have extra counters so it can have a running total of the increment its incrementing by so that when it finds a relationship say when the 10555 is incremented until the 6089 works out, to then increment by that number so that the 6089 works every time, and then skip even checking 6089 since it will work every time then.
went from 5.5~6 seconds to so fast printing those 3 lines during testing probably slowed it down
vs actually putting in y/n yes/no whatever text instead of numbers for cancel/continue if thats bad ui not having english/text option(s)
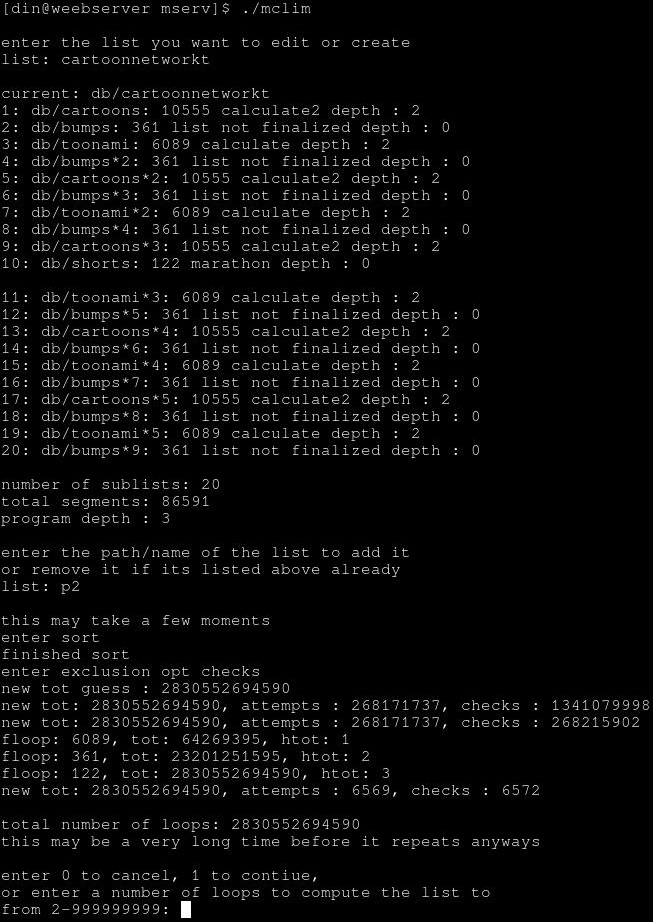
besides the general formatting that i think is close atleast, basically would be everything after this may take a few moments, until the line break will just be commented out as thats just debugging/testing output, and the last 2 blocks only print if the list is long like in the hundreds of thousands or longer
@TheDiddilyHorror do you have a recommendations for a blu-ray r/w drives if I wanted to start ripping my blu-rays with something like MakeMKV? I think I read somewhere its only possible on certain units and might have to flash custom firmware todo it and I’m not sure where to begin with that.
from quick lookin looked like asus or lg was the recommended, never looked at drive specifically but worked fine on my lg using make mkv
I have a techPulse120 which is just an LG BU40N in an enclosure.
You only need to flash the firmware if you want to use LibreDrive.
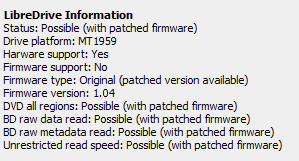
Not sure if it needs to be flashed to rip UHD BluRays (never tried that).
good to know. I kinda wanted one in 5.25, though I will see if I can find a similar LG drive in that format instead of a slim/enclosure if i can.
From what I’ve heard that appears to be the case that you need LibreDrive for UHDs and the newer drives on the market are locked down so they can’t be flashed for it, though I don’t currently own any UHD blu-rays so that’s not a huge deal breaker.